
sinewavespeech
An interactive website for exploring how human speech can be reduced extremely and still be intelligible.
Update 2024: This project can be found under sinewavespeech.com/explanation/. I later created a variant where you can play with the effect in real time, and sinewavespeech.com/ now points there. You can read more about that in this post.
If you’ve arrived here through the link on said website, welcome! I’m Václav Volhejn and this is my personal site. Here’s more about me.
The code is available here. The repo contains both the website and the Python library I made to create the sine wave speech.
What’s sine wave speech?
Although it wasn’t termed sine wave speech then, the concept was introduced in a widely-cited 1981 paper by Robert E. Remez et al. (The paper isn’t open-access, but they say there are ways to solve that problem.) The title is Speech Perception Without Traditional Speech Cues. The researchers were interested in the question of what information people use to understand speech and to even perceive sound as speech. By stripping down the sound so radically, they rule out most options.
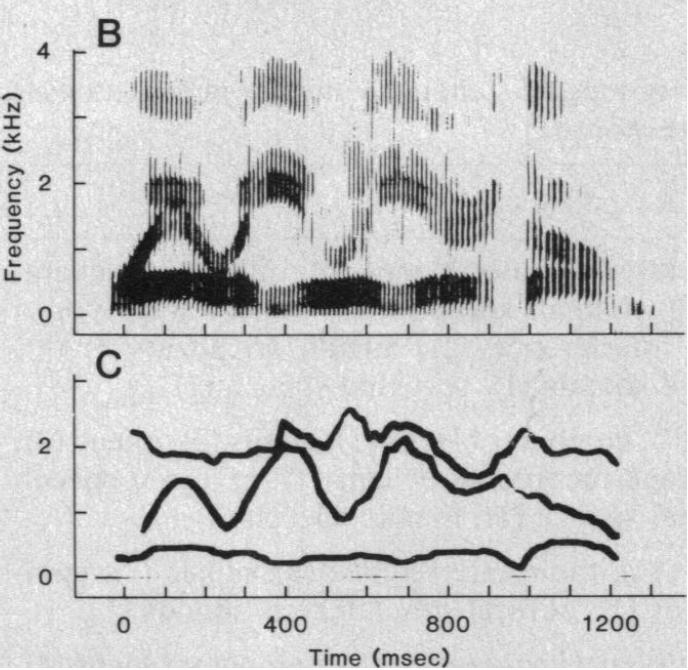
I like to think of sine wave speech as the auditory equivalent of biological motion perception:

It’s only a bunch of dots moving, but we still perceive them as a human walking. Similarly, it’s just a few sine waves, but we recognize they encode speech.
Apparently, researchers still aren’t sure how biological motion perception works, and its Wikipedia page has a lot more formulas than one would expect.
Why did you make sinewavespeech.com/explanation/?
I stumbled upon sine wave speech accidentally when researching something for my Master’s thesis and thought it was really cool.
But to my surprise, no Python implementations were around: the only implementation I found was one by Dan Ellis from 1996, from before I was born! So I made one myself.
Then in June 2023, I re-discovered MSCHF and got obsessed with their shenanigans. MSCHF is an art collective/brand that periodically releases “drops”: various small projects that are often conceptual and/or provocative. I intentionally used the vague term “project”: MSCHF drops are often fashion-related, like the Satan Shoes, modified Nike sneakers that contain blood. Sometimes, it’s just a big ol’ red boot.
But drops can also be things like thisfootdoesnotexist
A drop can also mean printing shirts that illegally use logos of major companies, and holding a race between companies about which one will be the first to submit a cease and desist letter. Subway won.
I love a lot of things about MSCHF, but particularly the way they present their drops. It’s always a beautifully designed standalone website, styled to match whatever that drop is. The feet pics one has text that’s styled as a messaging app history. The cease-and-desist one has formula cars C&D letters on them, and 3D renders of the shirts.
In a way, these are anachronisms, since most content is nowadays hosted on social media – said the guy with a personal website. But it’s clear that these drops wouldn’t fit into an Instagram post or a Tweet.
And that, finally, brings me to sinewavespeech.com/explanation/: I already had the Python library for SWS and I wanted to try presenting the concept with a unique standalone website. Then I had the idea of switching between the two versions of the audio using scrolling, and things clicked.
How does this work technically?
My implementation is based on Matlab code by Dan Ellis, code which is older than me (1994)! I started by translating the code to Python without really understanding what it does. I’m not an expert on digital signal processing and I don’t understand the math perfectly, but the basic idea is to use Linear Predictive Coding (LPC).

LPC is a technique that models speech as a filter applied to a simple source signal. This filter changes over time, and if it changes just right, it produces speech. Given some audio, you can compute how the LPC filter should change over time to produce that audio.
To get sine wave speech, you start by computing the LPC filter coefficients for each small chunk of audio (I used 32ms). Then instead of using it to reconstruct the original audio, you look for the resonance frequencies, the “peaks” of the filter – see the image above. You then take the 4 frequencies that form the biggest peaks and use those as the frequencies of your 4 sine waves. You can also infer how loud the sine wave should be at that time based on the peaks’ heights.
Once you’ve done this for every chunk of audio, you synthesize the sine wave speech version by playing sine waves at the frequencies and volumes that you’ve computed.
For a more detailed introduction to LPC, check out this tutorial.
Misc
I used Descript to record and edit the audio, and filtered it using their “Studio Sound” feature. The tool also allows you to export subtitles in .srt format, which is how I got the subtitles on sinewavespeech.com/explanation/.
I also stumbled upon this site where they experiment with quantizing sine wave speech to the frequencies you can play on a piano, so that you can turn your voice into something musical(-ish).



